

How compliance data actually flows
Most compliance setups work the same way. A customer initiates a transaction. The platform bundles up the details, wallet addresses, amounts, identity markers, and sends them via API to an external analytics provider. The provider runs the data against its models, returns a risk score, and the platform acts on it.
That satisfies AML requirements. From a data protection perspective, though, it usually means transferring personal data to servers in third-country jurisdictions. Under the GDPR, these transfers depend on Standard Contractual Clauses (SCCs) and Transfer Impact Assessments (TIAs). Managing all the supplementary measures around that adds real overhead to a firm’s data governance.
There is a second problem that gets less attention. Probabilistic clustering models, the industry standard for blockchain analytics, work by linking submitted addresses to broader clusters of related wallets. They map historical and predictive transaction graphs. A routine check on one customer may end up exposing sensitive data about counterparties and historical network interactions that have nothing to do with the original transaction nor any sanctioned transaction. Compliance teams need to think carefully about data minimisation (GDPR Article 5), purpose limitation, and whether they actually have a lawful basis for all of what they are processing.
Explainability and analytics models
Most established blockchain analytics providers run probabilistic clustering models powered by proprietary algorithms. These systems ingest large volumes of data to refine their statistical inferences and behavioural profiles over time.
For forensic investigations, this makes sense. Law enforcement tracing complex obfuscation techniques needs broad statistical inferences to reconstruct probable ownership chains.
Regulated Crypto-Asset Service Providers (CASPs) doing routine compliance have different needs. Sanctions screening and suspicious activity monitoring require explainability and precision. Leaning on probabilistic outputs for decisions that affect customers creates two specific problems.
Validating the false-positive and false-negative rates of a proprietary black-box model is difficult. That makes it harder to defend your risk scoring approach during an audit or in court. Separately, the EU Court of Justice’s SCHUFA ruling (C-634/21) suggests that relying on third-party probability scores to make determining decisions about a customer can count as “automated individual decision-making” under GDPR Article 22. The accountability for those decisions, and the obligation to explain them, stays with the CASP.
Forensics and routine compliance are different jobs
Privacy protocols and mixing services (CoinJoin, for example) create plausible deniability by breaking the deterministic link between input and output addresses. Probabilistic tools exist to pierce that deniability using statistical heuristics. Criminal investigations need that capability.
A CASP is not trying to prove ownership through a mixer to a judicial standard. A CASP screens against defined risks, identifies clear on-chain connections, and reports suspicious activity based on specific thresholds. Mixing up these two functions leads to over-processing data and more false positives that nobody can explain.
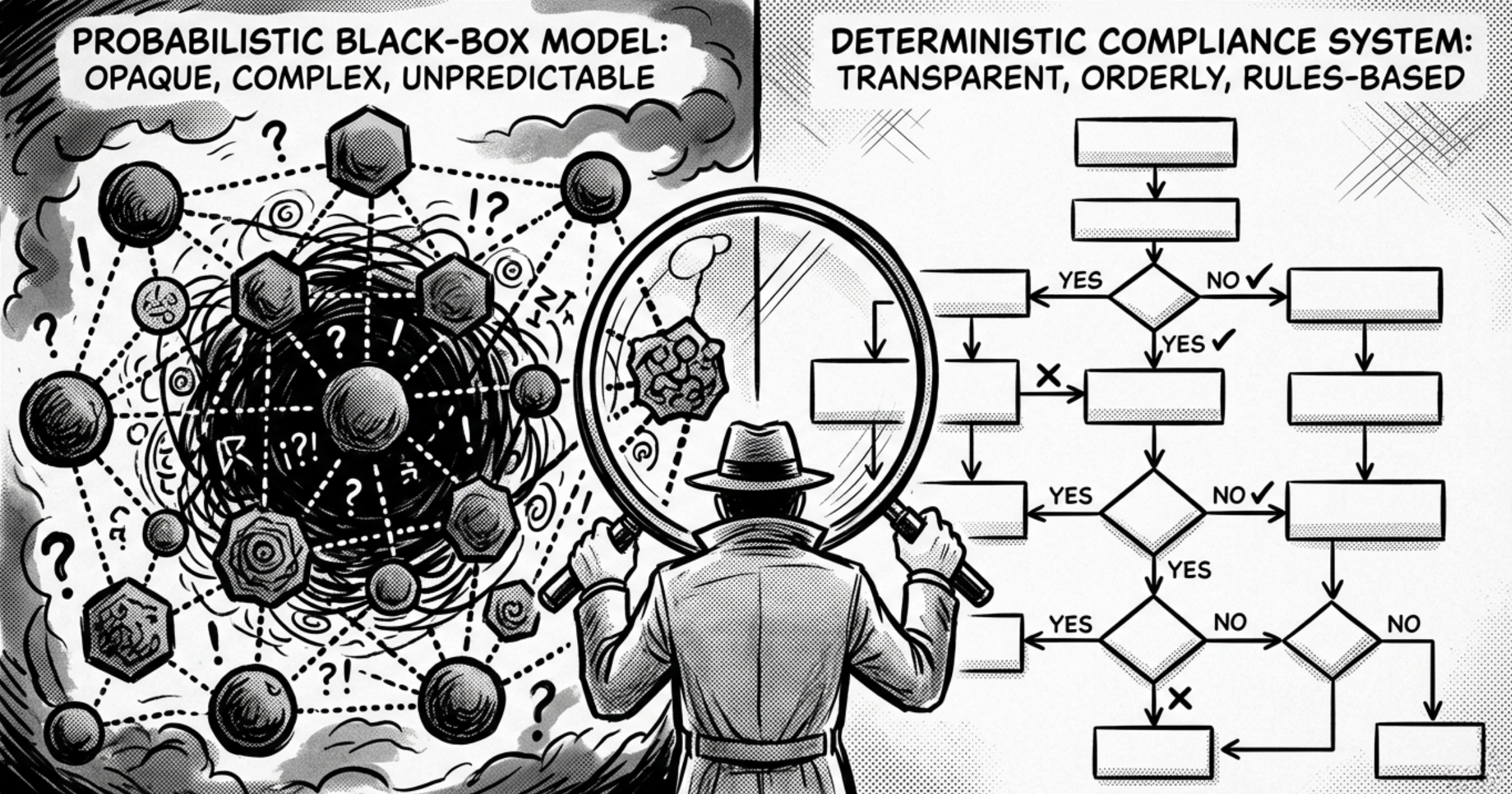
The case for deterministic architecture
A deterministic compliance system evaluates transactions against strictly defined, binary rules: direct sanctions list matches, known mixer usage, specific velocity or structuring thresholds.
Every flagged transaction maps back to a specific, transparent rule. When a supervisor asks why something was flagged, there is no proprietary algorithm to decode. The system triggers on exact data points rather than broad behavioural clustering, so data minimisation is baked into the architecture rather than patched on afterward. Deterministic systems identify objective risks and leave contextual interpretation and final decisions to trained compliance analysts, which lines up with what supervisors actually expect.
Opago’s compliance infrastructure uses this deterministic approach. Privacy by design is the starting point, and compliance teams get clear, binary evidence to base their risk weighting on.
Processing data internally
Where the processing happens matters as much as which model you use. Most setups rely on external API calls, but running compliance logic internally, inside the transaction infrastructure, has obvious advantages.
When compliance runs internally, customer data stays in the controlled environment. No third-party data transfers to manage. Simpler data controller agreements. No scramble to update Data Protection Impact Assessments (DPIAs) every time a vendor changes sub-processors. Internal processing also runs in milliseconds, which means actual real time transaction rails without waiting on external API round-trips.
What is coming from regulators
Three regulatory developments make these architectural choices worth thinking about now.
MiCA transitional periods wrap up by mid-2026. Getting a MiCA licence will mean showing that your AML/CFT obligations and GDPR compliance work together, not just coexist on paper. The EU AML Package and AMLA bring renewed supervisory focus on explainable, proportionate compliance with clear audit trails. And the forthcoming EDPB Guidelines 02/2025 on blockchain technology reinforce that privacy by design and data minimisation are mandatory. Blockchain’s immutability makes proportionate data handling even more important, not less.
Questions to ask your vendors
If you are evaluating or upgrading your monitoring architecture, a few questions can help during vendor assessment. What specific data leaves your controlled environment, and where does it get processed? Are compliance flags generated by your internal rulesets, or by the vendor’s proprietary model? Can the vendor provide a full methodology disclosure for their analytical models, so you can actually explain flagged transactions to a regulator? How does the architecture hold up against recent rulings on automated decision-making under GDPR Article 22?
Getting AML and data protection to work together is table stakes at this point. Understanding the structural differences between probabilistic and deterministic models is how compliance and technical teams avoid building something that satisfies one requirement at the expense of the other.
Want to explore what a privacy-first compliance architecture could look like for your organization? Get in touch.